【新科技讯】IBM最新发布的人工智能单元(AIU)是其首个片上系统设计。作为一种专用型集成电路(ASIC),AIU旨在训练和运行需要大规模并行算力的深度学习模型。与此前针对传统软件应用设计的CPU相比,AIU在深度学习处理方面的性能要强得多。IBM目前还未给出AIU的具体发布日期。

这款全新AIU芯片是IBM研究院AI硬件中心投入五年开发出的成果。AI硬件中心专注于开发下一代芯片与AI系统,计划每年将AI硬件效率提升2.5倍,并希望在十年间(2019年至2029年)将AI模型的训练和运行速度拉高1000倍。
AIU大解密
根据IBM发布的博文,“我们的完整片上系统共有32个处理核心和230亿个晶体管――与我们z16芯片的晶体管数量大致相同。IBM AIU在设计易用性方面与普通显卡相当,能够接入任何带有PCI插槽的计算机或服务器。”
深度学习模型在传统上,一直依赖于CPU加GPU协处理器的组合进行训练与运行。GPU最初是为沉浸图形图像而开发,但后来人们发现该技术在AI领域有着显著的使用优势。
IBM AIU并非图形处理器,而是专为深度学习模型加速而生,针对矩阵和矢量计算进行了设计优化。AIU能够解决高复杂度计算问题,并以远超CPU的速度执行数据分析。
AI与深度学习的发展
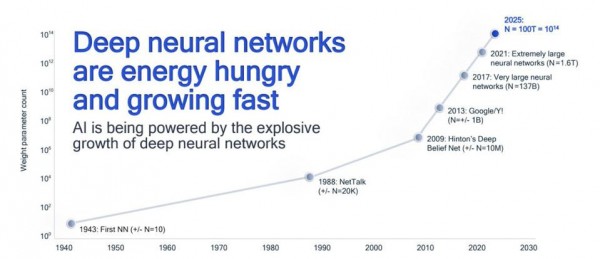
深度学习的发展给算力资源带来了巨大压力。AI与深度学习模型在各个行业的普及度呈现出指数级增长,如今几乎每个角落都浮动着智能元素的身影。
除了普及度提升之外,模型大小也堪称一路狂飙。深度学习模型往往体量庞大,包含数十亿甚至数万亿个参数。遗憾的是,根据IBM的说法,硬件效率的发展已经无法跟上深度学习的指数级膨胀。
近似计算
从历史上看,计算一般集中在高精度64位与32位浮点运算层面。但IBM认为,有些计算任务并不需要这样的精度,于是提出了降低传统计算精度的新术语――近似计算。IBM在博文中对于近似计算的基本原理做出如下说明:
“对于常见的深度学习任务,我们真的需要那么高的计算精度吗?没有高分辨率图像,难道我们的大脑就无法分辨家人或者小猫?当我们进行一轮文本线程搜索时,难道第50002条答案跟第50003条之间的顺序必须严格区分?答案当然是否定的,所以如此种种的诸多任务都可以通过近似计算来处理。”
近似计算在新AIU芯片的设计中也发挥着至关重要的作用。IBM研究人员设计的AIU芯片精度低于CPU,而这种较低精度也让新型AIU硬件加速器获得了更高的计算密度。IBM使用混合8位浮点(HFP)计算,而非AI训练中常见的32位或16点浮点计算。由于精度较低,因此该芯片的运算执行速度可达到FP16的2倍,同时继续保持类似的训练效能。
这种看似相互冲突的设计目标,在IBM眼中却是和谐统一、顺畅自然。具体来讲,既要靠低精度计算获得更高的算力密度和更快的计算速度,同时又要保证深度学习(DL)模型的准确率与高精度计算保持一致。
IBM设计的这款芯片就是为了简化AI工作流而生。蓝色巨人解释道,“由于大多数AI计算都涉及矩阵和矢量乘法,所以我们的芯片架构采用了比通用型CPU更简单的布局。IBM将AIU设计为直接将数据从一个计算引擎发送至另一计算引擎,由此大大削减了运行功耗。”
性能表现
IBM在公告中并未提到多少关于该芯片的技术信息。但回顾IBM在2021年国际固态电路会议(ISSCC)上展示的早期7纳米芯片设计性能,应该可以据此估算出最新AIU的大致性能水平。
IBM在会上展示的原型并非32核心,而一块实验性的4核心7纳米AI芯片,支持FP16与混合FP8格式,可用于深度学习模型的训练和推理。它还支持用于扩展推理的int4和int2格式。2021年Lindley Group在通讯中公布了这款原型芯片的性能摘要,相关报道如下:
在峰值速度并使用HFP 8时,这款7纳米芯片设计方案实现每秒每瓦特1.9 teraflops(TF/W)。 TOPS衡量的是加速器在1秒之内可以解决多少数学问题,可用于比较不同加速器在特定推理任务上的处理能力。在使用INT4进行推理时,这款实验芯片可达到16.5 TOPS/W,优于高通的低功耗Cloud AI模组。